Web Accessibility Evaluation Tool
Tag: WebDev
Web development news and tutorials
Gallery2
Your photos on your website
SitePoint.com
New Articles, Fresh Thinking for Web Developers and Designers
How to Run AI Agents 24/7: OpenClaw Hosting & Production Runtime Lessons
20 June 2026 @ 3:00 pm
How to Run AI Agents 24/7: OpenClaw Hosting and Production Runtime Lessons
20 June 2026 @ 7:00 am
null
Continue reading
How to Run AI Agents 24/7: OpenClaw Hosting and Production Runtime Lessons
on SitePoint.
Bounding Box Annotation for Document AI: What It Is, What It Produces, and Why It Matters for Model Training
18 June 2026 @ 3:00 pm
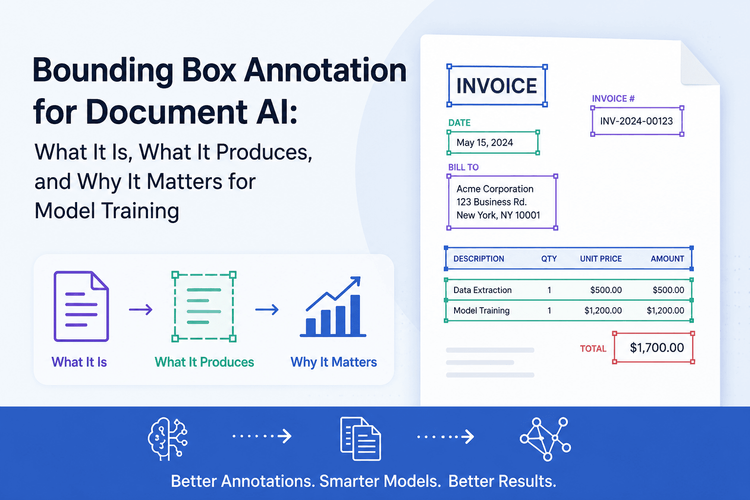 null
Continue reading
Bounding Box Annotation for Document AI: What It Is, What It Produces, and Why It Matters for Model Training
null
Continue reading
Bounding Box Annotation for Document AI: What It Is, What It Produces, and Why It Matters for Model TrainingPayment orchestration Platforms for Enterprises to watch in 2026
17 June 2026 @ 9:05 pm
 Compare the top payment orchestration platforms for enterprise merchants in 2026. Reviews Akurateco, Spreedly, Primer, Gr4vy, IXOPAY, and more on fit and features.
Continue reading
Payment orchestration Platforms for Enterprises to watch in 2026
on SitePoint.
Compare the top payment orchestration platforms for enterprise merchants in 2026. Reviews Akurateco, Spreedly, Primer, Gr4vy, IXOPAY, and more on fit and features.
Continue reading
Payment orchestration Platforms for Enterprises to watch in 2026
on SitePoint.
Build SVG Charts for Web Applications with Code Examples
17 June 2026 @ 7:17 pm
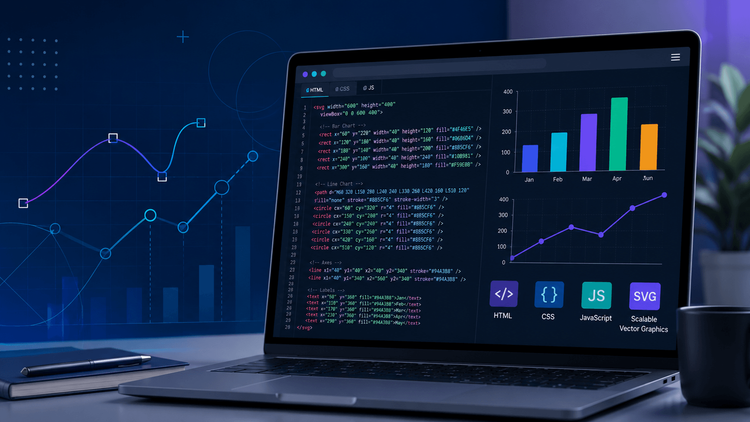 Build SVG charts for web applications from scratch using HTML and JavaScript. Covers bar charts, key SVG elements, and when to pick a charting library instead.
Continue reading
Build SVG Charts for Web Applications with Code Examples
on SitePoint
Build SVG charts for web applications from scratch using HTML and JavaScript. Covers bar charts, key SVG elements, and when to pick a charting library instead.
Continue reading
Build SVG Charts for Web Applications with Code Examples
on SitePointThe Hidden Challenge of Healthcare Analytics: Building Reliable Dashboards with Incomplete CMS Data
17 June 2026 @ 7:00 am
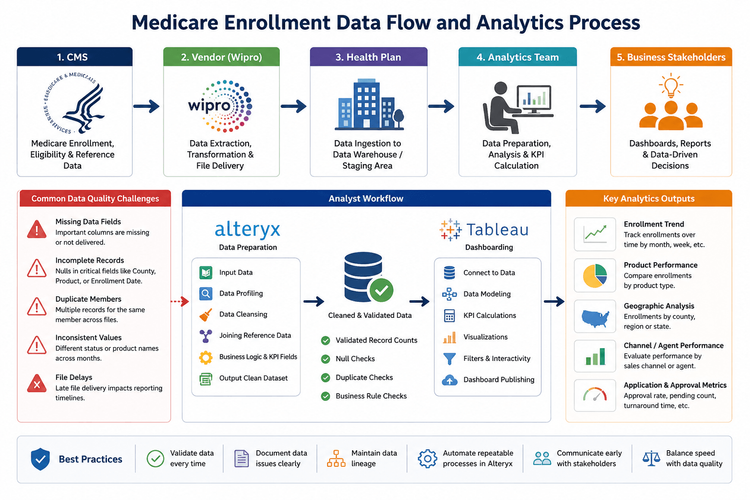 null
Continue reading
The Hidden Challenge of Healthcare Analytics: Building Reliable Dashboards with Incomplete CMS Data
on SitePoin
null
Continue reading
The Hidden Challenge of Healthcare Analytics: Building Reliable Dashboards with Incomplete CMS Data
on SitePoinBeyond Dashboards: How Predictive Analytics Is Transforming Healthcare Decision-Making
16 June 2026 @ 7:00 am
 null
Continue reading
Beyond Dashboards: How Predictive Analytics Is Transforming Healthcare Decision-Making
on SitePoint.
null
Continue reading
Beyond Dashboards: How Predictive Analytics Is Transforming Healthcare Decision-Making
on SitePoint.
Image Optimization for Core Web Vitals in 2026: What Actually Moves the Needle
13 June 2026 @ 7:00 am
 null
Continue reading
Image Optimization for Core Web Vitals in 2026: What Actually Moves the Needle
on SitePoint.
null
Continue reading
Image Optimization for Core Web Vitals in 2026: What Actually Moves the Needle
on SitePoint.
Building Interactive Charts in JavaScript: A Developer’s Guide
10 June 2026 @ 7:00 am
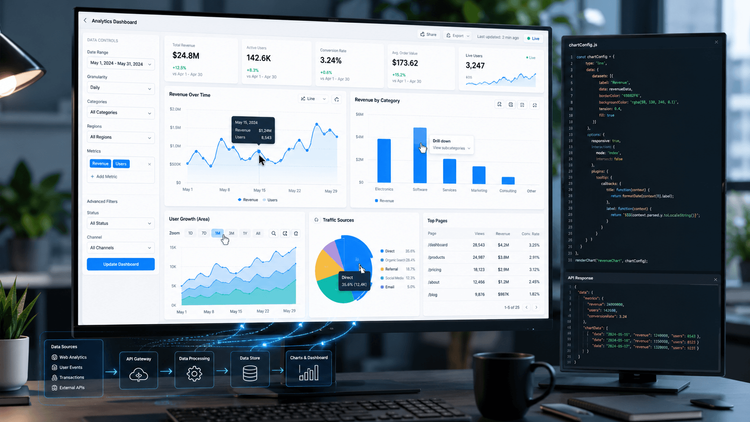 null
Continue reading
Building Interactive Charts in JavaScript: A Developer’s Guide
on SitePoint.
null
Continue reading
Building Interactive Charts in JavaScript: A Developer’s Guide
on SitePoint.
Sharing Content to Instagram Using Python
10 June 2026 @ 7:00 am
 null
Continue reading
Sharing Content to Instagram Using Python
on SitePoint.
null
Continue reading
Sharing Content to Instagram Using Python
on SitePoint.
Mon.itor.us
Free Websites Performance, Availability, Traffic Monitoring
DeGraeve.com
The Projects of Steven DeGraeve
DeGraeve.com
css.maxdesign.com.au
CSS resources and tutorials for web designers and web developers
DynamicDrive.com
DHTML(dynamic html) & JavaScript code library
ShowMeDo.com
Learning Python, Linux, Java, Ruby and more with Videos, Tutorials and Screencasts